Central Processing Unit中央處理器 本文取自維基百科


AMD Phenom Quad-Core處理器
中央處理器(英語:Central Processing Unit,CPU),是電腦的主要裝置之一。其功能主要是解釋電腦指令以及處理電腦軟體中的資料。所謂電腦的可編程性主要是指對CPU的編程。CPU、內部記憶體和輸入/輸出裝置是現代電腦的三大核心部件。由積體電路製造的CPU,20世紀70年代以前,本來是由多個獨立單元構成,後來發展出微處理器CPU複雜的電路可以做成單一微小功能強大的單元。
「中央處理器」這個名稱,籠統地說,是對一系列可以執行複雜的電腦程式的邏輯機器的描述。這個空泛的定義很容易地將在「CPU」這個名稱被普遍使用,之前的早期電腦也包括在內。無論如何,至少從20世紀60年代早期開始(Weik 1961),這個名稱及其縮寫已開始在電腦產業中得到廣泛應用。儘管與早期相比,「中央處理器」在實體形態、設計製造和具體任務的執行上有了戲劇性的發展,但是其基本的操作原理一直沒有改變。
早期的中央處理器通常是為大型及特定應用的電腦而定製。但是,這種昂貴的為特定應用定製CPU的方法很大程度上已經讓位於開發便宜、標準化、適用於一個或多個目的的處理器類。這個標準化趨勢始於由單個電晶體組成的大型電腦和微機年代,隨著積體電路的出現而加速。IC使得更為複雜的CPU可以在很小的空間中設計和製造(在微米的量級)。CPU的標準化和小型化都使得這一類數位裝置(港譯-電子零件)在現代生活中的出現頻率遠遠超過有限應用專用的電腦。現代微處理器出現在包括從汽車到手機到兒童玩具在內的各種物品中。
歷史

主條目:電腦硬體歷史
在現今的CPU出現之前,如同埃尼阿克之類的電腦在執行不同程式時,必須經過一番線路調整才能啟動。由於它們的線路必須被重設才能執行不同的程式,這些機器通常稱為「固定程式電腦」(fixed-program computer)。而由於CPU這個詞指稱為執行軟體(電腦程式)的裝置,那些最早與儲存程式型電腦一同登場的裝置也可以被稱為CPU。
儲存程式型電腦的主意早已呈現在ENIAC的設計上,但最終還是被省略以期早日完成。在1945年6月30日,ENIAC完成之前,著名數學家馮·紐曼發表名為"關於EDVAC的報告草案"的論文。它揭述儲存程式型電腦的計劃將在1949年正式完成(馮·紐曼1945)。EDVAC的標的是執行一定數量與種類的指令(或操作),這些指令結合產生出可以讓EDVAC執行的有用程式。特別的是,為EDVAC而寫的程式是儲存在高速電腦記憶體中,而非由實體線路組合而成。這項設計克服了ENIAC的某些局限——即花費大量時間與精力重設線路以執行新程式。在馮·紐曼的設計下,EDVAC可以藉由改變記憶體儲存的內容,簡單更換它執行的程式(軟體)。[1]
值得注意的是,儘管馮·紐曼由於設計了EDVAC,使得他在發展儲存程式型電腦上的貢獻最為顯著,但其他早於他的研究員如Konard Zuse也提出過類似的想法。另外早於EDVAC完成,利用哈佛架構製造的馬克一號,也利用打孔紙帶而非電子記憶體用作儲存程式的概念。馮·紐曼架構與哈佛架構最主要的不同在於後者將CPU指令與資料分開存放與處置,而前者使用相同的記憶體位元置。大多近代的CPU依照馮·紐曼架構設計,但哈佛架構一樣常見。
身為數位裝置,所有CPU處理不連續狀態,因此需要一些轉換與區分這些狀態的基礎元件。在市場接受電晶體前,繼電器與真空管常用在這些用途上。雖然這些材料速度上遠優於純粹的機械構造,但是它們有許多不可靠的地方。例如以繼電器建造直流按序邏輯迴路需要額外的硬體以應付接觸點跳動問題。而真空管不會有接觸點跳動問題,但它們必須在啟用前預熱,也必須同時停止運作。[2]通常當一根真空管壞了,CPU必須找出損壞元件以置換新管。因此早期的電子真空管式電腦快於電子繼電器式電腦,但維修不便。類似EDVAC的真空管電腦每隔八小時便會損壞一次,而較慢較早期的馬克一號卻不太發生故障(Weik 1961:238)。但在最後,由於速度優勢,真空管電腦支配當時的電腦世界,儘管它們需要較多的維護照顧。大多早期的同步CPU,其時脈頻率低於近代的微電子設計(見下列對於時脈頻率的討論)。那時常見的時脈頻率為100千赫茲到4百萬赫茲,大大受限於內建切換裝置的速度。
分立電晶體與積體電路 CPU

由於許多科技廠家投入更小更可靠的電子裝置,設計CPU變得越來越複雜。電晶體的面世便是第一個CPU的飛躍進步。1950到60年代的電晶體CPU不再以體積龐大、不可靠與易碎的開關元件(例如繼電器與真空管)建造。藉由這項改良,更複雜與可靠的CPU便被建造在一個或多個包含分立(離散)元件的印刷電路板上。
在此時期,將許多電晶體放置在擁擠空間中的方法大為普及。積體電路(IC)將大量的電晶體集中在一小塊半導體片,或晶片(chip)上。剛開始只有非常基本、非特定用途的數位電路小型化到IC上(例如NOR邏輯閘)。以這些預裝式IC為基礎的CPU稱為小規模積體電路(SSI)裝置。SSI IC,例如裝置在阿波羅導航電腦上的那些電腦,通常包含數十個電晶體。以SSI IC建構整個CPU需要數千個獨立的晶片,但與之前的分立電晶體設計相比,依然省下很多空間與電力。肇因於微電子科技的進步,在IC上的電晶體數量越來越大,因此減少了建構一個完整CPU需要的獨立IC數量。「中規模積體電路」(MSI)與「大規模積體電路」(LSI)將內含的電晶體數量增加到成百上萬。
1964年IBM推出了System/360電腦架構,此架構讓一系列速度與性能不同的IBM電腦可以執行相同的程式。此確實為一項創舉,因為當時的電腦大多互不相容,甚至同一家廠商製造的也是如此。為了實踐此項創舉,IBM提出了微程式概念,此概念依然廣泛使用在現代CPU上(Amdahl et al. 1964)。System/360架構由於太過成功,因此支配了大型電腦數十年之久,並留下一系列使用相似架構,名為IBM zSeries的現代主機產品。同一年(1964),迪吉多(DEC)推出另一個深具影響力且瞄準科學與研究市場的電腦,名為PDP-8。DEC稍後推出非常有名的PDP-11,此產品原先計劃以SSI IC構組,但在LSI技術成熟後改為LSI IC。與之前SSI和MSI的祖先相比,PDP-11的第一個LSI產品包含了一個只用了4個LSI IC的CPU(Digital Equipment Corporation 1975)。
電晶體電腦有許多前一代產品沒有的優點。除了可靠度與低耗電量之外,由於電晶體的狀態轉換時間比繼電器和真空管短得多,CPU也就擁有更快的速度。幸虧可靠度的提升與電晶體轉換器的切換時間縮短,CPU的時脈頻率在此時期達到十幾百萬赫茲。另外,由於分立電晶體與IC CPU的使用量大增,新的高性能設計,例如SIMD(單指令多資料)、向量處理機開始出現。這些早期的實驗性設計,刺激了之後超級電腦(例如克雷公司)的崛起。

主條目:微處理器
自從微處理器在1970年代發表之後,便大大影響了CPU的設計與實作。自1970年第一款微處理器Intel 4004與第一款廣受使用的Intel 8080在1974年發表以來,這型式的CPU幾乎完全取代了其他CPU的實作方法。當時的大型主機與微計算機-業者開發了專利IC的設計程式以改進他們的舊計算機架構,最終推出可以向下相容他們的舊硬體與軟體的指令集。與當時剛發展,並在之後普及大眾的個人電腦相結合。"CPU"這個詞現在幾乎等同於微處理器。
前幾世代的CPU實作,是在一或多個電路版上放置幾個分散的元件與數量眾多的小IC(積體電路)。而微處理器則是製作成幾個少量的IC,通常是一個。由於實體因素,例如降低寄生電容的門檻值,此種單晶片的小尺寸CPU設計讓它有更快的反應能力。這使得同步微處理器擁有數十兆赫到數百萬兆赫的執行頻率。另外,由於在一個IC放置小型電晶體的技術持續進步,在單個CPU上的電晶體數量與複雜度都在戲劇性地增加。此廣為人知的現象稱為摩爾定律,它成功預言了CPU與其他IC的複雜度與時俱增的性質。
由於前述的摩爾定律依舊沒有被打破,很自然地讓人想像IC與電晶體工業的極限何在。極端小型化電子閘門導致各種現象如電遷與次臨界漏電效應變得相當明顯。這些新效應使得研究人員試圖研發新的計算方法,例如量子電腦以及擴展平行運算和其他運用馮·紐曼模型的方法。
CPU運作原理
CPU的主要運作原理,不論其外觀,都是執行儲存於被稱為程式裡的一系列指令。在此討論的是遵循普遍的馮·紐曼架構設計的裝置。程式以一系列數位儲存在電腦記憶體中。差不多所有的馮·紐曼CPU的運作原理可分為四個階段:提取、解碼、執行和寫回。
第一階段,提取,從程式記憶體中檢索指令(為數值或一系列數值)。由程式計數器指定程式記憶體的位元置,程式計數器保存供識別目前程式位元置的數值。換言之,程式計數器記錄了CPU在目前程式裡的蹤跡。提取指令之後,PC根據指令式長度增加記憶體單元[iwordlength]。指令的提取常常必須從相對較慢的記憶體尋找,導致CPU等候指令的送入。這個問題主要被論及在現代處理器的快取和管線化架構(見下)。
CPU根據從記憶體提取到的指令來決定其執行行為。在解碼階段,指令被拆解為有意義的片斷。根據CPU的指令集架構(ISA)定義將數值解譯為指令[isa]。一部分的指令數值為運算碼,其指示要進行哪些運算。其它的數值通常供給指令必要的資訊,諸如一個加法運算的運算標的。這樣的運算標的也許提供一個常數值(即立即值),或是一個空間的定址值:暫存器或記憶體位址,以定址模式決定。在舊的設計中,CPU裡的指令解碼部分是無法改變的硬體裝置。不過在眾多抽象且複雜的CPU和ISA中,一個微程式時常用來幫助轉換指令為各種形態的訊號。這些微程式在已成品的CPU中往往可以重寫,方便變更解碼指令。
在提取和解碼階段之後,接著進入執行階段。該階段中,連接到各種能夠進行所需運算的CPU部件。例如,要求一個加法運算,自變數邏輯單位將會連接到一組輸入和一組輸出。輸入提供了要相加的數值,而且在輸出將含有總和結果。ALU內含電路系統,以於輸出端完成簡單的普通運算和邏輯運算(比如加法和位元運算)。如果加法運算產生一個對該CPU處理而言過大的結果,在標誌暫存器裡,溢位標誌可能會被設置(參見以下的數值精度探討)。
最終階段,寫回,以一定格式將執行階段的結果簡單的寫回。運算結果極常被寫進CPU內部的暫存器,以供隨後指令快速存取。在其它案例中,運算結果可能寫進速度較慢,但容量較大且較便宜的主記憶體。某些型式的指令會操作程式計數器,而不直接產生結果資料。這些一般稱作「跳轉」並在程式中帶來循環行為、條件性執行(透過條件跳轉)和函式[jumps]。許多指令也會改變標誌暫存器的狀態位元。這些標誌可用來影響程式行為,緣由於它們時常顯出各種運算結果。例如,以一個「比較」指令判斷兩個值的大小,根據比較結果在標誌暫存器上設置一個數值。這個標誌可藉由隨後的跳轉指令來決定程式動向。
在執行指令並寫回結果資料之後,程式計數器的值會遞增,反覆整個過程,下一個指令周期正常的提取下一個順序指令。如果完成的是跳轉指令,程式計數器將會修改成跳轉到的指令位址,且程式繼續正常執行。許多複雜的CPU可以一次提取多個指令、解碼,並且同時執行。這個部分一般涉及「經典RISC管線」,那些實際上是在眾多使用簡單CPU的電子裝置中快速普及(常稱為微控制器)[riscpipeline]。
設計與實作
整數表示法
CPU數字錶示方法是一個設計上的選擇,這個選擇影響了裝置的運作方式。一些早期的數位電腦內部使用電力模型來表示通用的十進制(基於10進位元)數位系統數位。還有一些罕見的電腦使用三進制表示數位。幾乎所有的現代的CPU使用二進制系統來表示數位,這樣數位可以用具有兩個值的實體量來表示,例如高低電位[binaryvoltage]等等。

與數表示相關的是一個CPU可以表示的數的大小和精度,在二進制CPU情形下,一個位元(bit)指的是CPU處理的數中的一個有意義的位元,CPU用來表示數的位元數量常常被稱作"字長", "位元寬", "資料通路寬度",或者當嚴格地涉及到整數(與此相對的是浮點數)時,稱作"整數精度",該數量因體系結構而異,且常常在完全相同的CPU的不同部件中也有所不同。例如:一個8位元的CPU可處理在八個二進制數碼(每個數碼具有兩個可能的取值,0或1)表示範圍內的數,也就是說,28或256個離散的數值。 實際上,整數精度在CPU可執行的軟體所能利用的整數取值範圍上設定了硬體限制。[softwareints]
整數精度也可影響到CPU可定址(定址)的記憶體數量。譬如,如果二進制的CPU使用32位元來表示記憶體位置,而每一個記憶體位置代表一個八位元組,CPU可定位元的容量便是232個位元組或4GB。以上是簡單描述的CPU位置空間,通常實際的CPU設計使用更為複雜的定址方法,例如為了以同樣的整數精度定址更多的記憶體而使用分頁技術。
更高的整數精度需要更多線路以支援更多的數位位元,也因此結構更複雜、更巨大、更花費能源,也通常更昂貴。因此儘管市面上有許多更高精準度的CPU(如 16,32,64甚至128位元),但依然可見應用軟體執行在4或8位元的微控制器上。越簡單的微控制器通常較便宜,花費較少能源,也因此產生較少熱量。這些都是設計電子裝置的主要考量。然而,在專業級的應用上,額外的精度給予的效益(大多是給予額外的位置空間)通常顯著影響它們的設計。為了同時得到高與低位元寬度的優點,許多CPU依照不同功用將各部分設計成不一樣的位元寬度。例如IBM System/370使用一個原為32位元的CPU,但它在其浮點單元使用了128位元精度,以得到更佳的精確度與浮點數的表示範圍 (Amdahl et al. 1964)。許多後來的CPU設計使用類似的混合位元寬,尤其當處理器設計為通用用途,因而需要合理的整數與浮點數運算算能力時。

主條目:時脈頻率
內頻=外頻×倍頻。
大部分的CPU,甚至大部分的按序邏輯裝置,本質上都是同步的。[seqlogic] 也就是說,它們被設計和使用的前提是假設都運作在一個同步訊號中。這個訊號,就是眾所周知的時脈訊號,通常是由一個周期性的方波(構成)。透過計算電訊號在CPU眾多電路中不同的分支中迴圈所需要的最大時間,設計者們可以為時脈訊號選擇一個適合的周期。
該周期必須比訊號在延遲最大的情況下移動或者傳播所需的時間更長。設計整個CPU在時脈訊號的上升沿和下降沿附近移動資料是可能的。無論是在設計還是元件的維度看來,均對簡化CPU有顯著的優點。同時,它也存在CPU必須等候回應較慢元件的缺點。此限制已透過多種增加CPU平行運算的方法下被大幅的補償了。(見下文)
無論如何,結構上的改良無法解決所有同步CPU的弊病。比方說,時脈訊號易受其它的電子訊號影響。在逐漸複雜的CPU中,越來越高的時脈頻率使其更難與整個單元的時脈訊號同步。是故近代的CPU傾向發展多個相同的時脈訊號,以避免單一訊號的延遲使得整個CPU失靈。另一個主要的問題是,時脈訊號的增加亦使得CPU產生的熱能增加。持續變動的時脈頻率使得許多元件切換(Switch)而不論它們是否處於運作狀態。一般來說,一個處於切換狀態的元件比處於靜止狀態還要耗費更多的能源。因此,時脈頻率的增加使得CPU需要更有效率的冷卻方案。
其中一個處理切換不必要元件的方法稱為時脈閘控,即關閉對不必要元件的時脈頻率(有效的停用元件)。但此法被認為太難實行而不見其低耗能通用性。 另一個對通用時脈訊號的方法是同時移除時脈訊號。當移除通用時脈訊號;使得設計的程式更加複雜時,非同步(或無時脈)設計使其在能源消耗與產生熱能的維度上更有優勢。罕見的是,所有的CPU建造在沒有利用通用時脈訊號的狀況。兩個值得注意的範例是ARM("Advanced RISC Machine")順從AMULET以及MIPS R3000相容MiniMIPS。與其完全移除時脈訊號,部份CPU的設計允許一定比例的裝置不同步,比方說使用不同步自變數邏輯單位元連接上標管線以達成一部份的自變數效能增進。在不將時脈訊號完全移除的情況下,不同步的設計可使其表現出比同步計數器更少的數學運算。因此,結合了不同步設計極佳的能源耗損量及熱能產生率,使它更適合在嵌入式電腦上運作。 (Garside et al. 1999).
平行
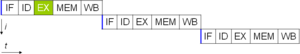
下標量CPU的運算過程示意。注意其需要15個循環以完成三個指令。
主條目:平行計算
這一型式的CPU有一很大的缺點:效率低。由於只能執行一個指令,此類的處理給與下標量CPU原生的低效能。由於每次僅有一個指令能夠被執行,CPU必須等到上個指令完成才能繼續執行。如此便造成下純量CPU延宕在需要兩個以上的時脈循環才能完成的指令。即便增加第二個執行單元(見下文)也不會大幅提升效能;除了單一通道的延宕以外,雙通道的延宕及未使用的電晶體數量亦增加了。如此的設計使得不論CPU可使用的資源有多少,都僅能一次執行一個指令並可能達到純量的效能(一個指令需一個時脈循環)。無論如何,大部份的效能均為下純量(一個指令需超過一個時脈循環)。
為了達成純量標的以及更佳的效能,導致使得CPU傾向平行運算的各種設計越來越多。提到CPU的平行,有兩個字彙常用來區分這些設計的技術。指令平行處理(Instruction Level Parallelism, ILP)以增加CPU執行指令的速率(換句話說,增加on-die執行資源的利用),以及執行緒平行處理(Thread Level Parallelism, TLP)目的在增加執行緒(有效的個別程式)使得CPU可以同時執行。每種方法均可由其如何嵌入或相對有效(對CPU的效能)來區分。[parallelperformance]

基本的管線結構示意。假設在最佳情況下,這種管線可以使CPU維持純量的效能。
其中一種達成增加平行運算的方法,便是在主要指令完成執行之前,便進行指令提取及解碼。這種最簡易的技術,我們稱為指令管線,且其被利用在泰半現代的泛用CPU中。透過分解執行通道至離散階段,指令管線化可以兩個以上的指令同時執行。相較於已被淘汰的組合管線,指令管線化不再使用等候指令完全在管線中結束才執行下一指令的技術。
指令管線化產生了下一作業需要前一作業才可完成的可能性。此類狀況又常稱為相依衝突。解決的方法是,對此類的情況增加額外的注意,及在相依衝突發生時延遲一部份的指令。自然地,此種解決方法需要額外的循環,是故指令管線化的處理器比下標量處理器還要複雜。(雖然不是很顯著)一個指令管線化的處理器的效能可能十分接近純量,只需停用管線推遲即可。(在一個階段需要超過一個以上的循環的指令)

簡單的上純量管線。藉由同時提取和分派兩個指令,能夠在一個時脈循環中完成最多兩個指令。
此外,對於指令管線化的改進啟發了減少CPU元件閒置時間的技術。稱為超純量的設計包括了一條長指令管線化及多個相同的執行單元。上純量管線的分派器同時讀取及透過數個指令;分派器決定指令是否能夠平行執行(同時執行)並分配到可執行的執行單元。大致上來說,一個上純量的CPU能夠同時分派越多的 指令給閒置的執行單元,就能夠完成越多的指令。
上純量CPU結構的設計中,最困難的部份便是創造一個有效率的分派器。分派器必須能夠快速且正確的決定指令是否能夠平行執行,並且讓閒置的執行單元最小化。其需要指令管線化常時的充滿指令流,且提升了在上純量結構中一定數量的CPU快取。其亦催生了危害迴避的技術,如分支預測、投機執行與跨序執行以維持高層次的效能。藉由嘗試預測特定的指令選擇何分支(路徑),CPU能夠最小化整個指令管線等待特定的指令完成的次數。投機執行則是藉著執行部份的指令以得知其是否在整個作業完成後仍被需要而提供適度的效能提升。跨序執行則是重新整理指令執行的命令以降低資料相依。
當不是所有的CPU元件均有上純量效能時,未達上純量的元件效能便會因定序推遲而降低。奔騰的原型有兩個每一時脈循環可接收一個指令的上純量算術邏輯單元,但其浮點算術處理器(Floating Point Unit, FPU)不能在每一時脈循環接收一個指令。因此P5的效能只能算是整數上純量而非浮點上純量。英特爾Pentium結構的下一代P6加入了浮點運算處理器的上純量能力,因此在浮點指令上有顯著的效能提升。
此兩種簡單的管線及上純量設計,均能透過允許單一處理器在一個時脈迴圈完成一個指令[ipcrate] ,提升指令管線化的效能。多數的近代CPU設計至少都在上純量以上,且幾乎所有十年內的泛用CPU均達上純量。近年來,一些重視高指令管線化的電腦將其從CPU的硬體移至軟體。超長指令字元(的策略使得一部份的指令管線化成為軟體,減少CPU推動指令管線化的運作量,並降低了CPU的設計複雜度。
另一個常用以增加CPU:平行運算效能的策略是讓CPU有同時執行多個執行緒(程式)的能力。大致上說來,高同時執行緒平行執行(TLP)CPU比高指令平行執行來的有用。許多由Cray公司於1970年代及1980年代晚期所首創的同時執行緒平行執行,專於該方法而啟發了龐大的計算效力。(就時間上而言)事實上,TLP多執行緒運算自從1950年就已經開始被運用了(Smotherman 2005)。在單處理器設計中,兩種主要實作TLP的設計方法是晶片級多處理(CMP)晶片層多執行緒處理和simultaneous multithreading(SMT)。同級別層多執行緒處理。在更高階層中,一台電腦中有多個單獨的處理器,常常運用對稱多處理機(SMP)和non-uniform memory access(NUMA)非獨立記憶體存取的方式來結織。這些非常不同的方法,全部為了實作同一個標的,就是增加CPU同時處理多個執行緒的能力。
CMP和SMP這兩種方法其實是非常相似的,而且是最直接的方法。這裡有一些概念上的東西關於如何實兩個或是兩個以上完全單獨的CPU。在CMP中,多個處理器核心會被放入同一個包中,有時會在非常相近的積體電路中。另一方面SMP包含多個包在其中,NUMA和SMP很相像,但是nUMA使用非單一的記憶體存取方式。這些對於一台有著多個CPU的電腦來說是非常重要的,因為每個處理器存取記憶體的時間會很快的被SMP分享的模組消耗掉,因些會造成很嚴重的延遲,因為CPU要等待可用的記憶體.這是NUMA是個不錯的選擇,它可以允許有多個CPU同時存在一台電腦中而且SMP也可以同時實作.SMT有一些不同之處,就是SMT會儘可能的減少CPU處理能力的分布。TLP的實作實際上和超純量體系結構的實作有些相似,其實上它常常被用在超純量體系結構處理器中,如IBM的POWER5。相比於複製整個CPU,SMT會複製需要的部分來提取指令,加密和分配,就像記算機中的一般的暫存器一樣。因此這樣會使SMT CPU保持處理單位元其作的連續性,因些通常會提供給處理單位元多個指令而且來自不同的軟體執行緒,這和LTP結構很相似。相比於處理多個指令來自同一個執行緒,它會同時處理來自不執行緒的多個指令。
向量處理器與SIMD

上面提及過的處理器都是一些常量儀器[scalarvector],而針對向量處理的 CPU 是較不常見的型式,但它的重要性卻越來越高。事實上,在電腦計算上,向量處理是很常見的。顧名思義,向量處理器能在一個命令週期(one instruction)處理多項數據,這有別於只能在一個命令週期內處理單一數據的常量處理器。 這兩種不同處理數據的方法,普遍分別稱為『單指令,多資料』(SIMD)及『單指令,單資料』(SISD)。向量處理器最大的優點就是能夠在同一個命令週期中對不同的運作進行最佳化,例如:求一大堆數據的總和及向量的積dot product,更典型的例子就是多媒體應用程式(畫像、影像、及聲音)與及眾多不同總類的科學及工程上的運作。當常量處理器只能針對一組數據於單一命令週期內完全執行提取、解碼、執行和寫回四個階段的同時,向量處理器已能對較大型的數據如相同時間內執行相同動作。當然,這假設了這個應用程式於單一命令週期內對處理器進行多次要求。
大多數早期的向量處理器,例如Cray-1,大多都只會用於和科研及密碼學有關的應用程式。但是,隨著多媒體向數位媒體轉移,對於能做到『單指令,多資料』的普通用途處理器需求大增。於是,在浮點計算器普及化不久,擁有『單指令,多資料』功能的普通用途處理器便面世了。有些早期的『單指令,多資料』規格,如英特爾的MMX,只能作整數運算。因為大多數要求『單指令,多資料』的應用程式都要處理浮點數位,所以這個規格對軟體開發者無疑是一個主要障礙。幸好,這些早期的設計慢慢地被改進和重新設計為現時普遍的『單指令,多資料』新規格,AMD公司也推出了第一個真正能執行浮點SIMD指令集3DNow!,在每個時脈週期可得到4個單精確度浮點數結果,是當時一般x87浮點處理器的4倍。新規格通常都於一 ISA 關連著。近年,一些值得注意的例子一定要數英特爾的SSE和PowerPC相關的 AltiVec(亦稱為VMX)。[mmxsse]
備註
1. ^ 因為程式計數器記錄的是記憶體位置,而不是指令,所以它的增長取決於指令在記憶體中所佔的單位元數。在固定長度指令ISA中,每個指令所佔用的記憶體單位元是相同的。例如一個32位元的ISA固定長度指令將使用8位元記憶體單位元,而且每次將增加4個PC單位元。使用變數長度的ISA指令,如x86,它的PC在記憶體中的增長量取決於最後一個指令的長度。這裡要注意的是在更複雜的CPU中,最後一個指令的執行不一定會導至PC單位元的增長,特別的是在大量資料傳輸和超純量體系結構中。
2. ^ 因為CPU指令集的結構是基於它的介面和使用方法,所以它經常用來區別CPU的"種類"。例如一個PowerPC CPU會用到許多不的Power ISA 變數。有一些CPU,如英特爾Itanium,可以解譯多個ISA指令;不過這項運作大多由軟體來完成。多於直接將它在硬體中實作。(參見模擬器)
5. ^ 實體概念上的電位是一種模擬值,實際上可能的值可以有無限多種。為了實體上表達二進制數,我們把特定範圍的電位的值定為1或者是0。電位的範圍通常是構建CPU的部件的運作參數,例如電晶體的閾值限制,所決定。
6. ^ 當CPU的整數精確度範圍被限制的時候,它可以透過軟體和硬體技術相互合作的方法來克服。當我們使用額外的記憶體時,軟體可以處理比CPU限制大幾個數量級的整數。有時CPU的ISA也會提供相關的指令,幫助軟體更快速地處理大整數。雖然這種處理大整數的方法會比使用擁有高整數精確度的CPU要慢一些,對於處理那些需要大精確度整數的應用,它是一種可取的方法,特別是整數精確度的原生支援成本過高的時候。
9. ^ 我們要注意的是不管是ILP或TLP都不可以做為對方的上層控制。它們在增強CPU平行處理能力上有著不同的意義。它們有著各自的優缺點,而且取決於CPU可處理軟體種類。 High-TLP CPUs 經常被用來處理一些可以很自身分解成許多小程式的軟體中.因而稱它為 "embarrassingly parallel problems." 因此high TLP 設計方法可以連續快速的處理一些運算問題,比如SMP會使用太多的時間來處理ILP裝置(超純量體系結構的CPU),反之亦然。
12. ^ 因TPL的使用比ILP時間更長,所以晶片層多處理技術或多或少的只可以在以後的基於積體電路的微處理器。積體電路多處理技術中看到。導至這種情況的原因是,它不在適和早期的分立元件裝置,而且也只被運用了幾年(1990-2000),如今注意力都集中在設計高運算能力的CPU,這些CPU都運用了超純量結構的IPC設計方案,如英特爾Pentium 4。儘管如此,以前的技術似乎又被運用到現在CPU設計中來,又換回到稍底層的High -TLP傳輸中。它表現在增值雙核或多核CMP的設計中,如英特爾最新的設計中少了一些超純量體系結構的設計p6,之後的CPU多運用了CMP,包括x86-64、Opteron和Athlon 64 x2,還有Sparc UltraSparc T1,IBM Power4和Power5。還有一些其它的視訊遊戲機的CPU,如x360中的三核PowerPC設計。
著名公司
以下公司曾經或正在生產中央處理器;包含已經倒閉、結束市場或被併購的公司。
§ AMD(超微)
§ ARM(安謀)
§ DEC(迪吉多)
§ IDT
§ Intersil
§ MHS
§ MIPS
§ NexGen
§ OKI(沖電氣)
§ OPTi
§ Rise
§ Rockwell
§ SGS
§ Synertek
§ Sun(昇陽)
§ UMC(聯電)
§ VIA(威盛)
§ ZiLOG
沒有留言:
張貼留言